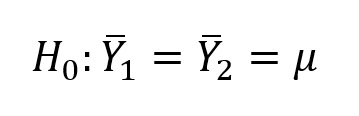
Up to this point, we have considered only 2-tailed probabilities, where the type I error rate (α) is distributed evenly between the 2 tails of the distribution. For the standardized deviates that we have been doing comparisons with, this means that we would reject the H0 for standarized deviates exceeding the critical value reported by the table, and also reject the H0 for standarized deviates less than the negative of the critical value reported by the table (because the t-distribution is symmetrical, only the positive values are reported in the table).
This means that we only are testing whether there is a difference between 2 means (or between a sample mean and a population mean). In other words, the alternate hypothesis to:
Is:
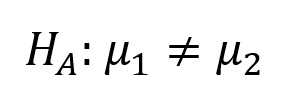
For a 2-tailed test. It does not matter which of the 2 means is larger, the null hypothesis will be rejected if the difference between them is great enough. Let us recall the trematode example. The question being asked was, based on testis size, whether the sample belonged to Halipegus eschi. This would be an example of a 2-tailed question, because we don't care in what direction the difference lies. We want to reject samples with a mean testis diameter that is too large to have come from the statistical population with μ = 320 μm, and also reject samples where the mean testis diameter is too small to have come from the statistical population with μ = 320 μm.
There are, however, instances when your hypothesis should be directional. Consider the same test that we applied to the trematode sample applied to the amount of rat feces present in a sample of flour. The FDA allows 9 milligrams of rodent fecal material in each kilogram of wheat, so if we take 9 mg as μ, we can compare the mean mass of rodent feces from a series of 19 samples to this standard. Clearly we do not want to reject flour that has less than 9 mg/kg of feces (a negative value for the sample mean minus the population mean), and so we would apply a 1-tailed test, using the α(1) probabilities on Table B.3. A one-tailed test takes the type I error rate (α) and applies it to only one side of the distribution:
If the animation does not work, or if you want to examine the individual graphs, they can be viewed HERE.
Compare the critical values at a single value of v on Table B.3 for α(1) = 0.05, and α(2) = 0.05, and you will see that the critical values are smaller for α(1), as indicated in the graph above. In this instance, the alternate hypothesis to the null hypotheses:
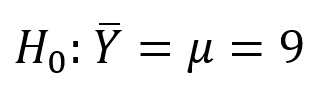
Would be:
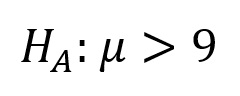
Because we only would reject samples that we concluded had higher than 9 mg of feces/kg (a positive value for the sample mean minus the population mean). The probability that you apply to your result will depend upon your specific experimental question, but if you are applying one-tailed probabilities, you will need to have a clear expectation for the sign of the difference you are examining, i.e., do you expect the difference between means as calculated to be either positive or negative? Another way of looking at it would be to consider whether you would reject your working hypothesis for any difference (greater than or less than), or only for a difference that occured in a specific direction, e.g., only greater than. The latter circumstance is referred to as having a directional hypothesis, and requires the application of a 1-tailed test.
Question 5: For the following working hypotheses or predictions, decide whether you should apply a 1-tailed test, or a 2-tailed test, and provide the justification for your answer.
Pronetharol should reduce blood pressure by competing for adrenergic beta receptors.
Increased water temperatures of a reservoir, as the result of using reservoir water to cool machinery in an electricity generating plant, should alter the zooplankton diversity of the reservoir.
The metabolic cost of infection should result in an increase in the amount of time spent foraging by odonate naiads infected with Haematoloechus floedae.
Different brands of fertilizer with the same N-P-K ratios will produce different growth rates in Brassica rapa.
One last piece of terminology that I will introduce is the use of the word significance as it applies to inferential statistics. The use of the word "significant" in the context of a conclusion, e.g., the mean testis diameter of the trematodes isolated from R. vaillanti was significantly larger than 320 μm, indicates that you have rejected a null hypothesis with a type I error rate (α) = 0.05, or in other words, p < 0.05. Having read that, you are now prevented from using the word "significant" in any other way. Substantial, important, compelling, and momentous all are synonyms for the way that you might have used "significant" in the past, and so use them wisely, and reserve the word "significant" for reporting the results of your analyses.
I also will leave you with 2 caveats regarding statistical significance. The first is that finding statistical significance does not imply biological significance. Yes I just used "significance" in the colloquial sense. Do as I say, not as I do. The second caveat has to do with the, so-called, p-value. These should be interpreted with caution. Anyone with any understanding of probabilities should recognize that a probability of 0.049 is really no different from a probability of 0.051 but, because of our decision rule, the former might be a cause of great celebration, and the latter might lead to weeks of depression.
I have seen p-values on the order of 0.051 referred to as "marginally significant" because they are suggestive, but not grounds to reject the H0. A moment of thought should bring you to realize that a more appropriate description would be "marginally non-significant" (the word "insignificant" has no statistical meaning whatsoever, and so you may continue to use it as you please...just not as a means of denoting that a null hypothesis was accepted). Rather than muddying the waters by trying to make our objective decision rule more subjective by finding new descriptors for "close, but no cigar", I would propose the following classification of decisions based on p-values (which I have stolen from a source that I cannot recall):
p < 0.025 : a significant result (reject H0 at α = 0.05)
0.025 < p < 0.075 : an inconclusive result (increase the sample size and try again)
p > 0.075 : a non-significant result (accept H0 at α = 0.05)
Although this week's material does not get a lot of coverage in your text, it is critical that you have a full understanding of it if you are to understand the basis of the analyses that we will conduct over the next several weeks. There is no Excel work for you to do this week (we will more than make up for that next week), so please take the time to review this material to insure that you can meet the objectives described below. If you have a good understanding of the material that we covered this week, next week will be pretty straightforward, but next week is typically when the wheels come off...
Save your Word document with your answers as yourlastnameex6, and submit it via Blackboard.
Week 6 Objectives
Be able to define null hypothesis, decision rule, type I error, and type II error
Be able to explain the concept of a standardized deviate
Understand what a null distribution represents, and how this relates to the critical values on statistical tables
Know how to estimate the p-value using the critical vales on a statistical table
Be able to explain the tradeoff between type I (α) and type II (β) error rates
Understand the concept of the power of a test as it relates to β
Understand the circumstances that call for a 1-tailed test or for a 2-tailed test
Be able to explain the phrase "statistical significance"
Send comments, suggestions, and corrections to: Derek Zelmer