The option of data transformation to meet assumptions has been mentioned several times as a possible (and more powerful) alternative to nonparametric approaches. Transformation of data for least-squares linear regression greatly expands the utility of the analysis by allowing its application to nonlinear relationships. Before we get too far along, please realize that data transformation is not cheating! Transformation merely changes the scale at which the observations are analyzed and/or reported.
Least squares linear regression has 4 main assumptions, 2 of which we already have touched upon, i.e., the assumption of a causal and linear relationship between the independent (X) and dependent (Y) variable. In addition to those assumptions, we assume that the values of Y are normally distributed around each value of X (we are only going to consider model I regression, which assumes that X is measured without error), and we assume that those distributions are all homoscedastic, i.e., they have equal variances.
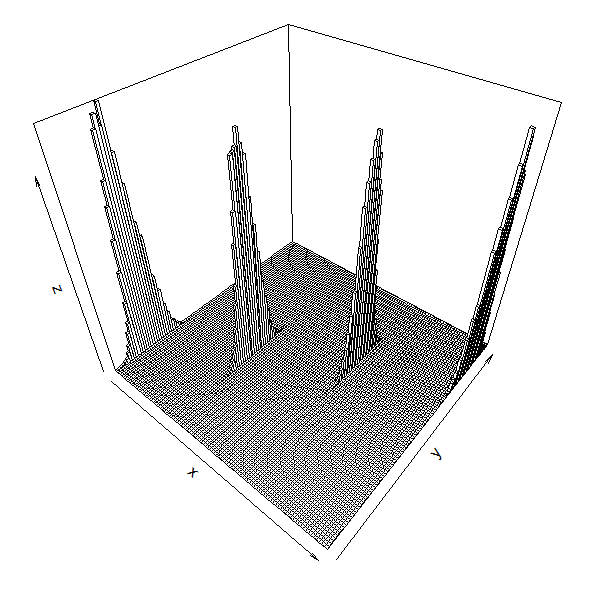
I have tried to depict these assumptions below. Just imagine that the graph has been tipped away from you so that the frequency distributions of the observations (Y around each value of X can be observed. The line of best fit would pass through the base of the distributions:
As you can (hopefully) see, for each of the 4 values of X, there is a symmetrical distribution of the values of Y, and the width of the 4 distributions is comparable. When dealing with data that have this structure (numerous observations for each value of X), we can apply our conventional tests for the assumptions, using the Shapiro-Wilk test for the observations associated with each value of X, and Bartlett's test (or the Fmax test) to examine the variances across the values of X.
We will address transformation to meet the homogeneity of variance assumption momentarily (even though it is best to conduct the variance transformation first, as it might cure a non-normality issue as well), but if the normality assumption is violated, transformation will essentially be a process of trial and error: transform the observations for the dependent variable, test for normality of the transformed observations (which we will designate as Y'), and repeat. Some common transformations are log transformation (Y' = log(Y)), square root transformation (Y' = sqrt(Y)) and reciprocal square root transformation (Y' = 1/(sqrt(Y))).
There is one instance where you will almost certainly need to apply a known transformation to the dependent variable, and that is when you are working with proportions. Because proportions are bounded by 0 and 1, the distribution tends to be narrower than a normal distribution when the central tendency is near 0.5, and becomes skewed as central tendencies approach 0 or 1. Arcsin transformation will generally fix this, where Y' = asin(sqrt(Y))-0.2853982. The units of Y' are radians. The 0.2853982 that is subtracted is the difference between asin(0.5) and 0.5, so subtracting that difference serves to keep 0.5 as the center of the distribution, while extending the tails from 0 and 1 to -0.2853982 and 1.285398.
In Excel, the formula for the transformation would be: =ASIN(SQRT(Y))-0.2853982.
Transformation to meet the normality assumption follows the same process as described above for the analyses that we already have covered that share the assumption of normally distributed error terms (single-sample t-test, 2-sample t-test, and ANOVA).
In a large number of instances (including the data sets for this week's assignment) you will not have a sufficient number of observations for each value of X to conduct statistical tests of the assumptions. Fear not! Although the normality issue will have to remain a large question mark, we can still do our due diligence by examining residual plots.
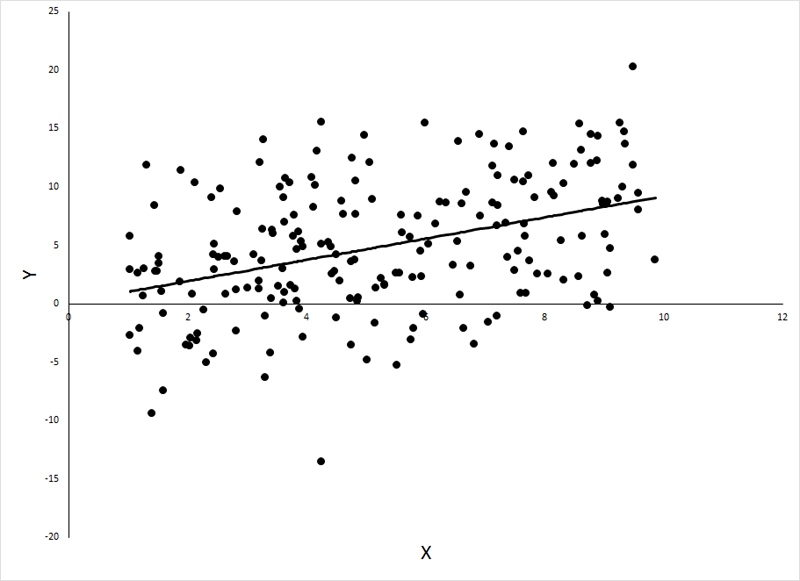
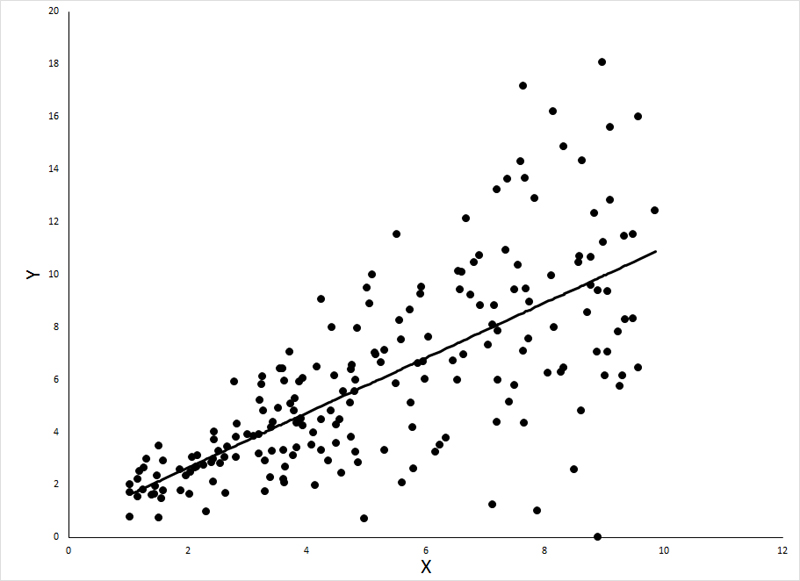
Below is a hypothetical, linear relationship between X and Y, showing the regression line passing through the observations:
Remember that we calculate residuals as:
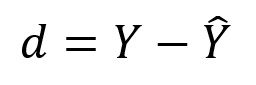
If we plot the residuals against X (or the value of Y estimated by the regression), we produce what is referred to as a residual plot:
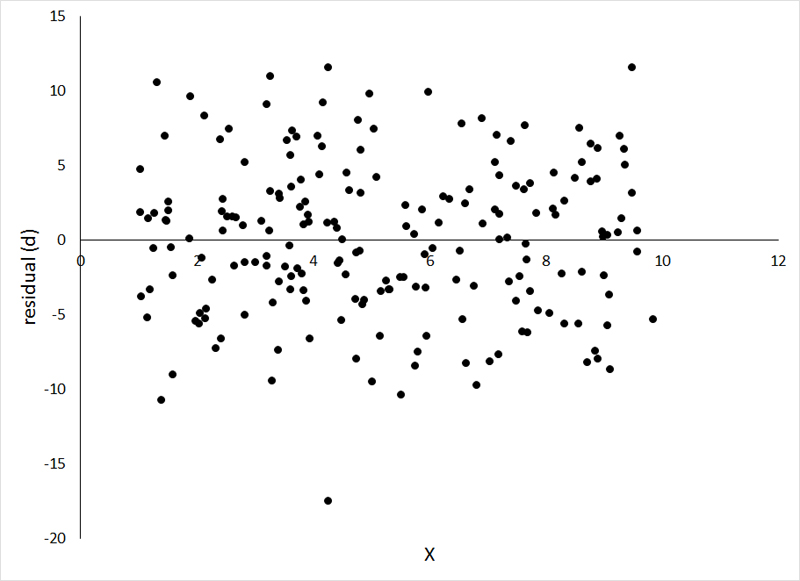
The horizontal line running through zero on the Y-axis represents our regression line, allowing us to visualize the distribution of the observations around the line. You could have done this with the preceding figure by tilting your head to the left (which is the technique that I employ), but the residual plot gives you a clearer picture. The plot above is exactly what we hope to see, with the distribution of the points around the line remaining constant across all values of X. This suggests (strongly) that the homogeneity of variance assumption has been met. We also can (to a much lesser degree) evaluate the spread of the observations as a (really poor) way of examining the normality assumption. There should be more observations closer to zero (on the Y-axis) than further from zero.
It is worth mentioning that there are extensions of the linear model approach that allow you to specify the distribution of the residuals around the regression line when the residuals are demonstrated (or expected) to deviate from normality. These approaches are referred to as generalized linear models (GLMs). The application of GLMs is beyond the scope of this course, but it is worth remembering that they exist because of their utility in dealing with non-normally distributed data.
For this week's exercise, we will not concern ourselves with the normality assumption (apart from remembering the importance of the arcsine transformation for proportions). We will focus only on the assumption of linearity, and the assumption of homogeneity of variance (i.e., homoscedasticity).
The most common violation of the assumption of homoscedasticity (homogeneity of variance) is where the variance is proportional to the mean value of Y. An example of such a violation can be seen below:
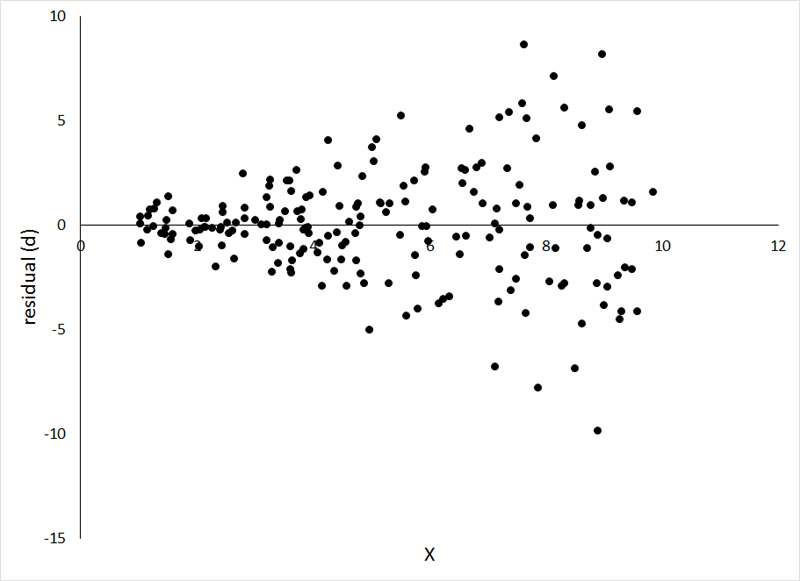
This heteroscedasticity (heterogeneity of variance) will look like a wedge on the residual plot:
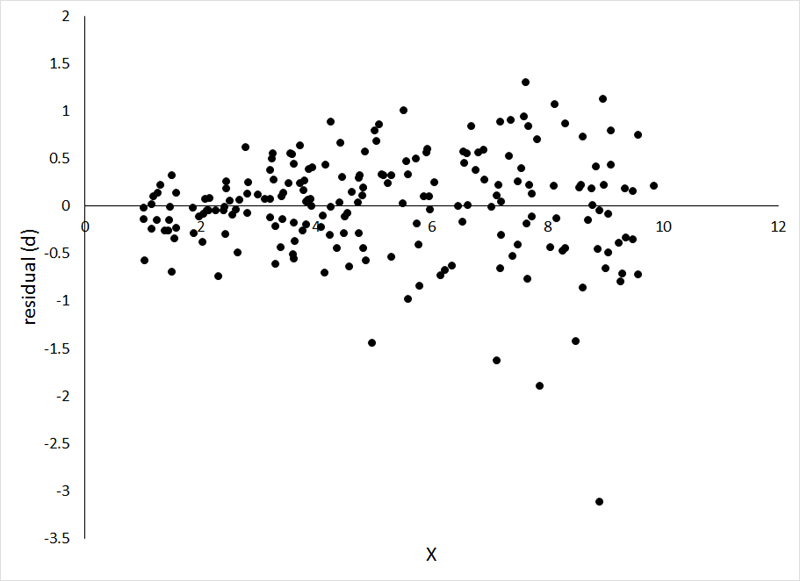
In this instance, the variance in Y is directly proportional to the estimated value of Y, and the best option is square root transformation of the observations (Y'=sqrt(Y)). Running regression analysis on the transformed data (Y') produces a residual plot that looks much better behaved:
Other transformations that can stabilize the variance when the residuals produce a wedge pattern are the log transformation (Y' = log(Y) or Y' = ln(Y)), which works well when the variance is proportional to the square of the estimate of Y, the reciprocal square root transformation (Y' = 1/sqrt(Y)), which works well when the variance is proportional to the cube of estimate of Y, and reciprocal transformation (Y' = 1/Y), which works well when the variance proportional to Y4. For the most part, this will be a trial and error process, with the end result being improved precision of your estimates of α and β. The good news is that a wedge pattern such as that shown above, will not bias the estimates of α and β (the Y-intercept and slope, respectively).
(FUN FACT: the transformations mentioned above also can be applied to categorical data for a t-test or ANOVA to try and correct a violation of the assumption of homoscedasticity.)
And now we come back to the beginning. What if your residual plot looks like this?
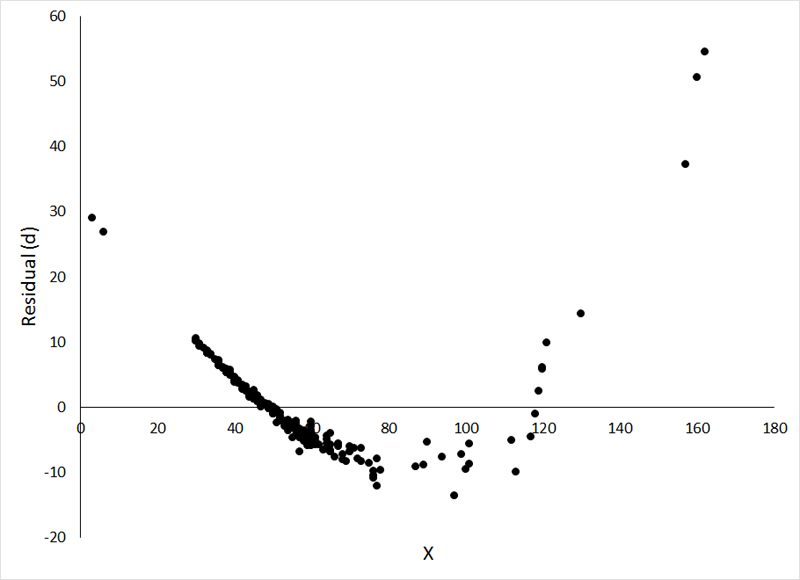
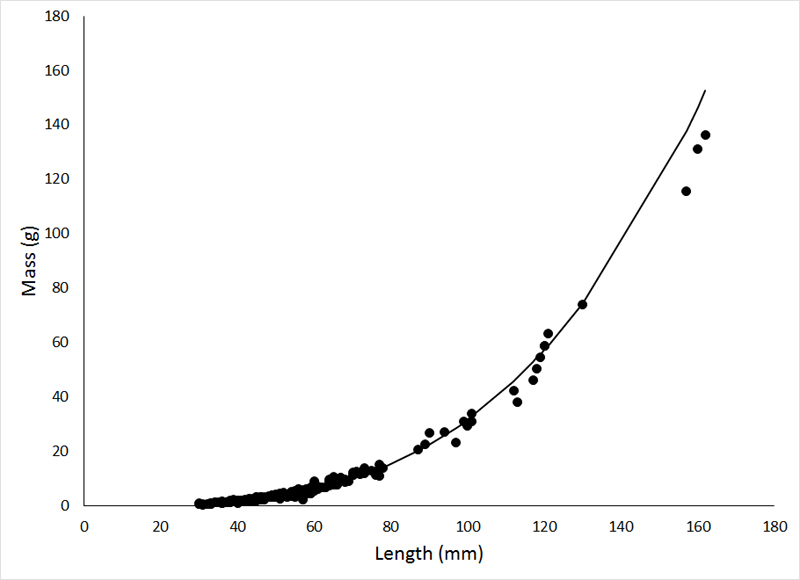
A residual plot like this means that you weren't paying any attention at all to the data before conducting the analysis. The first step to ANY analysis should always be to plot and examine the data. The pattern of residuals seen above is the result of trying to fit a straight line to a curvilinear relationship. It might seem like this would be a difficult mistake to make, but I have seen it done more than once. The data (a relationship between sunfish mass and sunfish length) are plotted below, with the ill-advised regression line from the above residual plot:
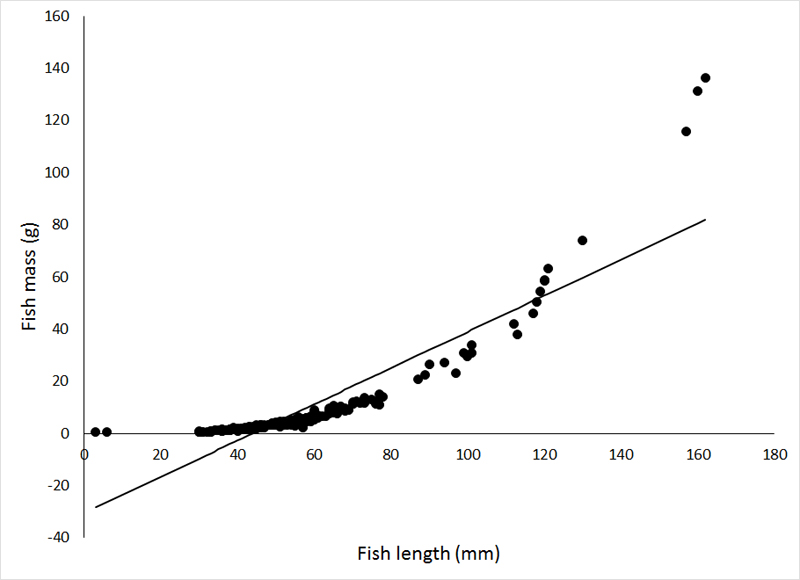
Clearly, the assumption of a linear relationship is violated in this example. Unlike transformations that seek to stabilize the variance, or improve normality, when transforming data to make a relationship linear, it is generally the independent variable (X) that is transformed. This is an important point. I have seen a lot of cases where transformations were applied for no particular reason, or because they were common transformations. Transformation of the data should be done only to correct a known issue with the data. For regression, it is the independent variable (X) that is first transformed to try and meet the linearity assumption. If this fails, transformation of the dependent variable may be attempted (double log transformation, i.e., log transformation of both variables, can make a straight line out of almost anything!). As an aside, relationships that are not linear, but can be transformed to become linear are referred to as intrinsically linear.
My approach to addressing transformations for linearity is to transform the independent variable in several ways, and simply plot the data to see which relationship appears to be the most linear. For this data set the most common transformations for the independent variable failed to linearize the relationship, and so a double log plot was employed:
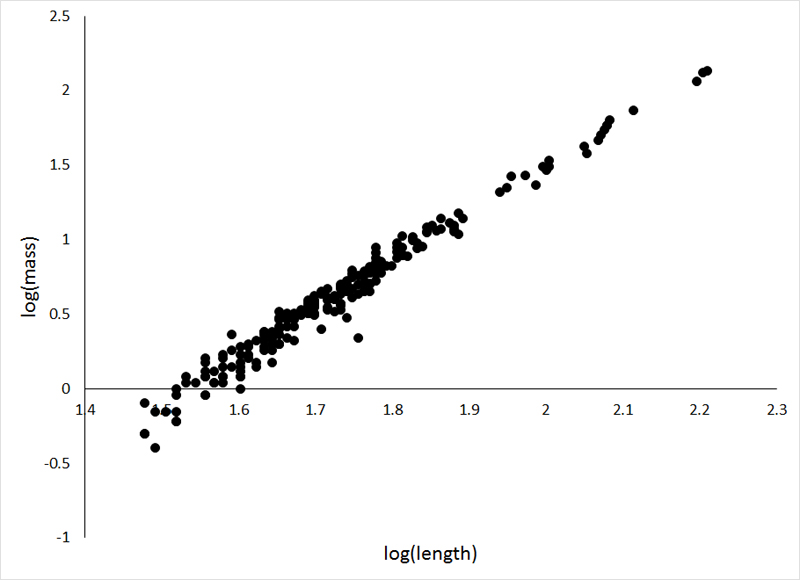
The double log transformation did make the relationship linear. If you tilt your head to the left, it may look as though there are variance issues, but the apparent wedge pattern in this case is simply the result of having very few observations of larger fish (it's a demography thing...). Regression analysis on the transformed data demonstrated a significant positive relationship (ts = 91.51, df = 1; p < 0.0001). The issue now is that we do not wish to present the double log plot of the data, as it is not easy to visualize the actual relationship between mass and length. In other words, we need to back transform our variables. The relationship determined for this analysis is:
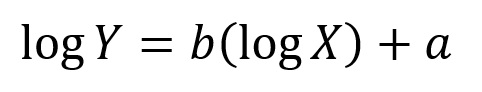
The equation takes this form because we did the regression analysis analysis on the logarithm of Y and the logarithm of X instead of on the actual values of Y and X. Make certain that you understand this before going further! The slope and Y-intercept that were derived are for the relationship between the log of X and the log of Y.
In order to calculate an estimate of Y (mass) for each value of X (length), we just need to use a little algebra (make each side of the equation an exponent of 10) to solve for Y:
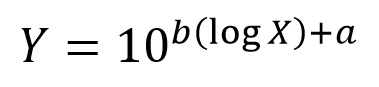
This will allow us to plot the data at the original scale, and give us a curved regression line that will make us look oh so clever:
In the preceding example, transformation of both the dependent variable and independent variable was required to achieve linearity. As mentioned previously, one should first attempt to make the relationship linear by transformation of the independent variable only. The figures below show examples of curvilinear relationships that can be made linear by transformation of the independent variable, so that you can get an idea of what transformations to try for specific patterns. The first example shows an intrisically linear function that can be made linear through square root transformation of the independent variable:
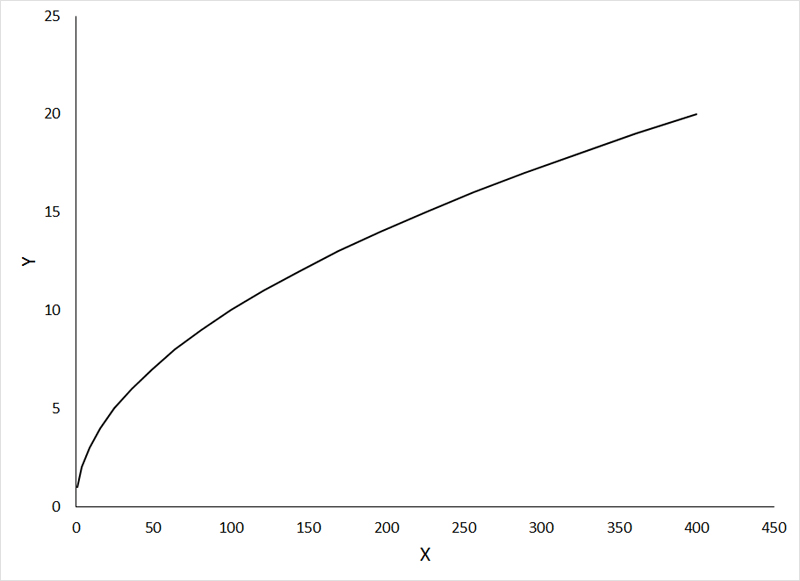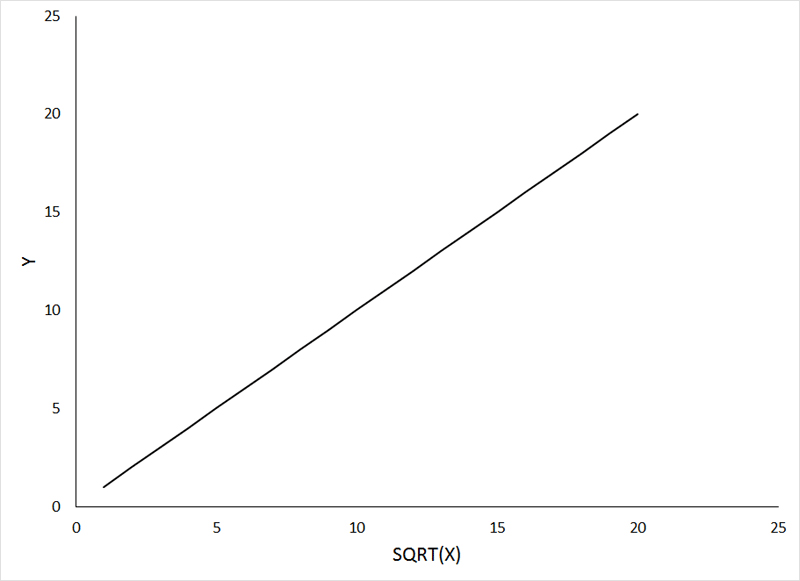
If the animation does not work, or if you want to examine the individual graphs, they can be viewed HERE.
The following figures depict a relationship that can be made linear by inverse transformation (X' = 1 / X) of the independent variable:
If the animation does not work, or if you want to examine the individual graphs, they can be viewed HERE.
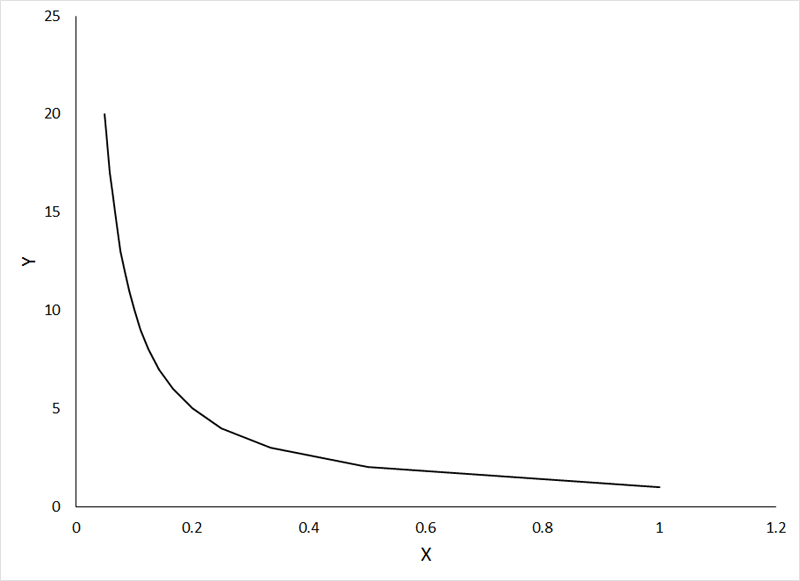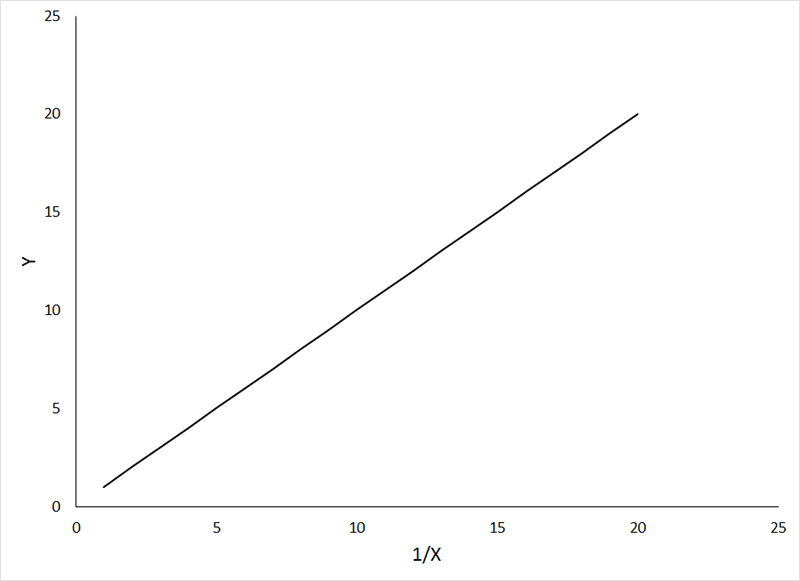
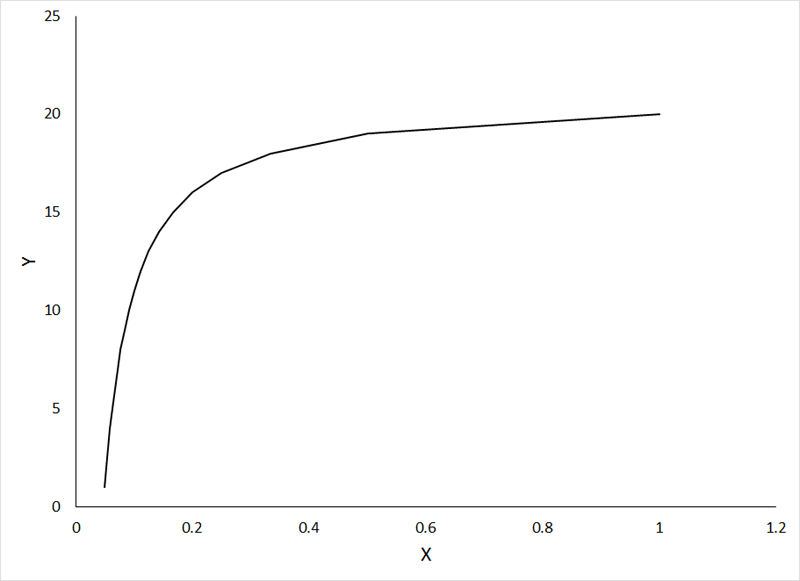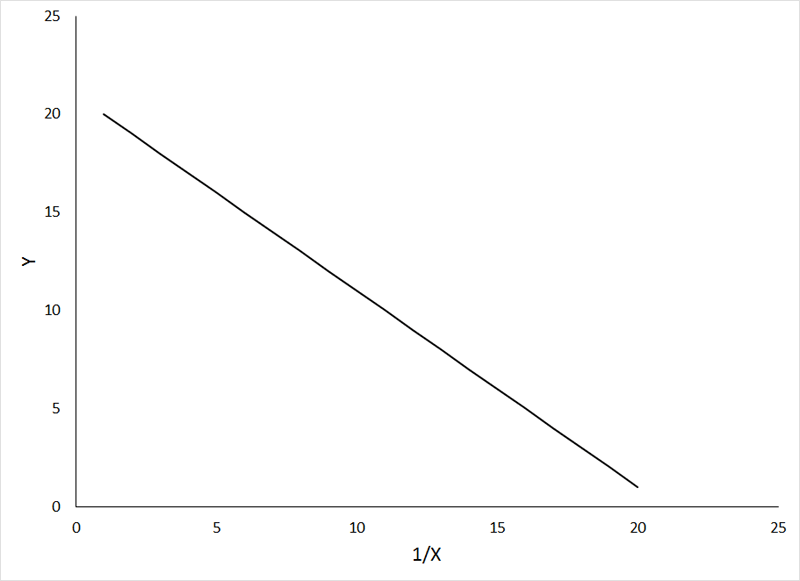
The following relationship also can be made linear by inverse transformation (X' = 1 / X) of the independent variable:
If the animation does not work, or if you want to examine the individual graphs, they can be viewed HERE.
Do not be concerned that the direction of the relationship changes with inverse transformation. Once you have completed the regression analysis, and completed the back transformation (by solving for Y), your curved line should fit the data nicely.
One of the most common transformations is the log transformation. It is so popular that it often is applied without any real reason for doing so! The following relationships are examples of the types of curvilinear relationships that can be made linear by log transformation (X' = log X) of the independent variable, for a positive relationship:
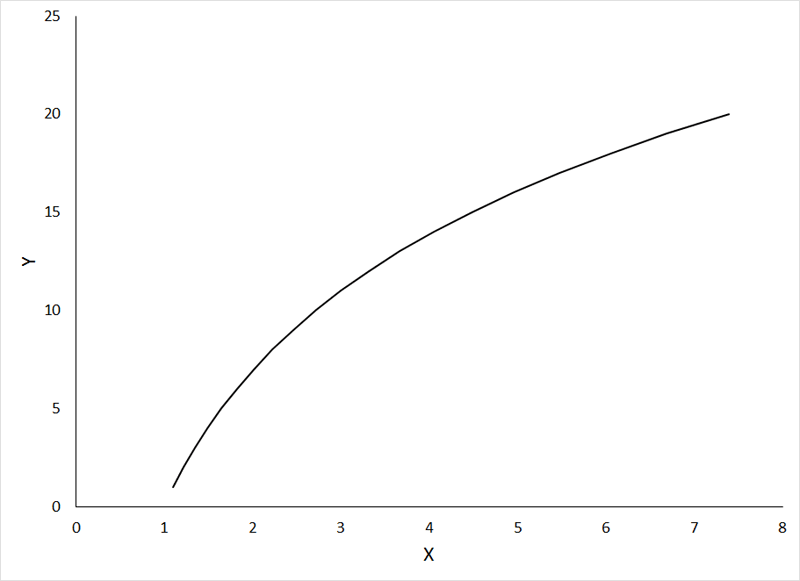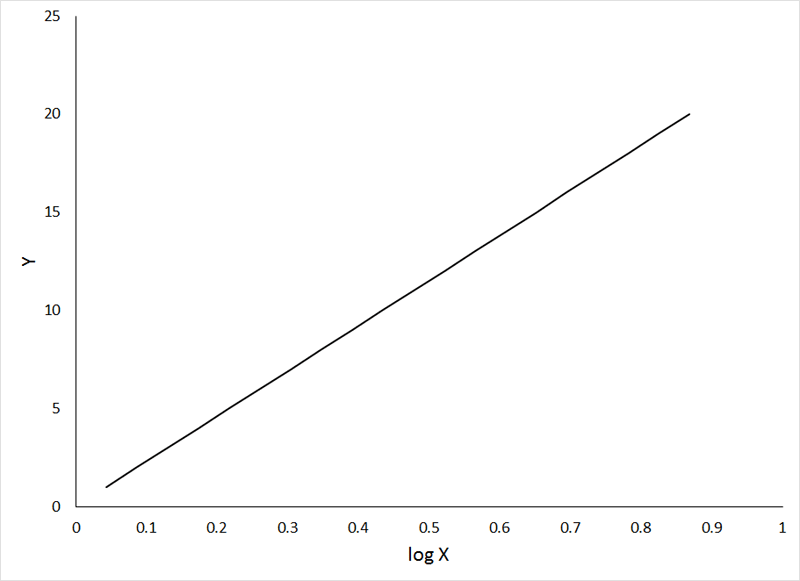
If the animation does not work, or if you want to examine the individual graphs, they can be viewed HERE.
Or a negative relationship:
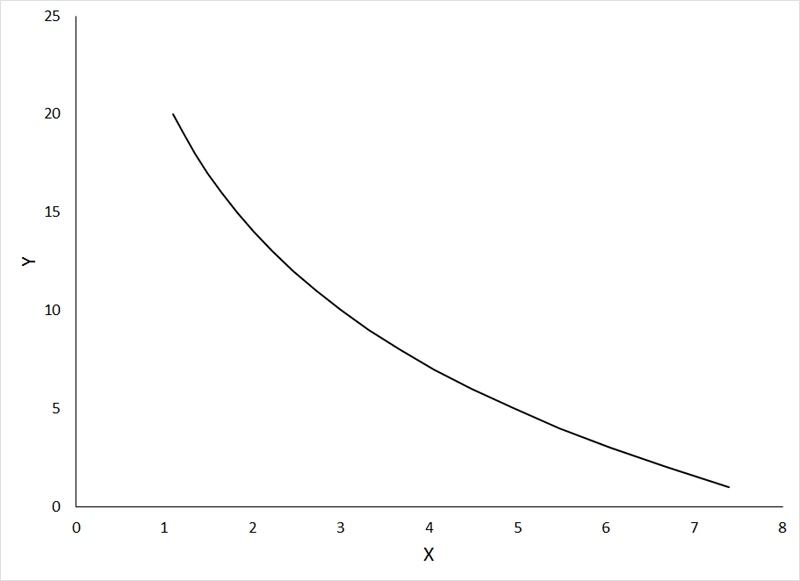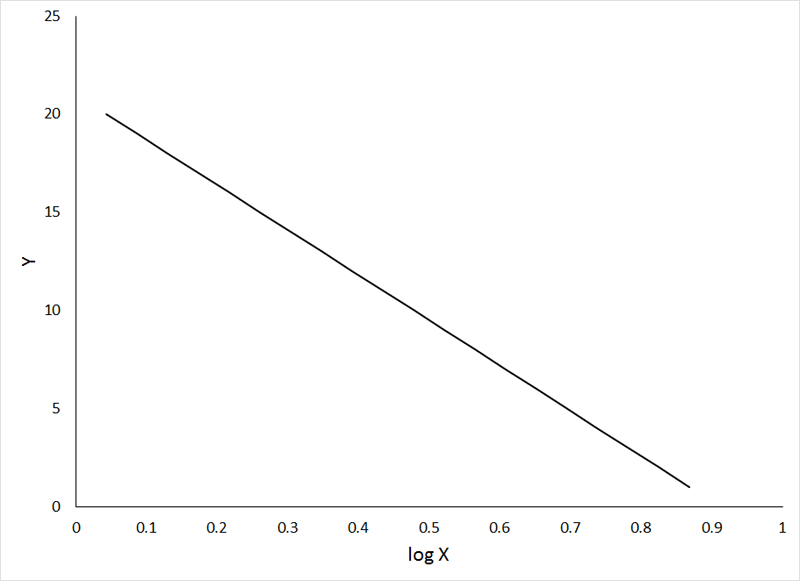
If the animation does not work, or if you want to examine the individual graphs, they can be viewed HERE.
We have covered a lot of possible transformations, and so now would be a good time to summarize the steps involved in transformation for least-squares linear regression. The first step is always to graph the data. Violations of the linearity and homoscedasticity assumptions should be detectable to the trained eye. For the untrained eye (and a good practice for even the most trained of eyes), run the regression analysis on the data, and plot the residuals so that you can examine the pattern.
If the relationship looks linear, examine the spread of the residuals to see if there are any issues with homoscedasticity. Remember the points around the line should be equidistant along the line. If you do see a wedge or double-wedge pattern, look carefully to make sure that it isn't just the result of having a small number of observations where the wedge is "thin". If there are clear homoscedasticity issues, adrress those by evaluating different transformations of the dependent variable (Y).
If it looks like there is a linearity issue, things become a little more difficult. As mentioned earlier, the first step should be to try and correct any variance issues, but that can be harder to do when the relationship is not linear, because you can't plot a reference line. There are statistical tools that can be used to directly address the assumption, but we are just going to apply the same visual principles that we would if the relationship were linear. Envision the curvilinear trend that would fit the data, and look for wedge patterns along that line. If you examine the figure below, it should give you an idea of what a homoscedastic curvilinear relationship looks like (on the left), and what that relationship would look like (on the right) with heteroscedasticity (specifically with the variance proportional to the mean):
![]()
Once you find a transformation that makes the variance a little better behaved, then you can try some transformations of the independent variable to see if the resulting relationship becomes more linear. This is something that can be done with a basic graph, but "it looked good to me" is probably not a justification you will want to, or will be able to successfully defend for a presentation or publication. An objective criterion for distinguishing among transformations is the r2 value. The best transformation should have the highest r2 value. If the transformation produces something that is clearly not linear, the graphical evidence will suffice. For this exercise, you only will need to compare r2 values if you cannot clearly distinguish between valid transformations by visual inspection of the graphs.
In some cases, transforming to make the relationship more linear may counteract your previous transformation for homoscedasticity, so you may have to experiment with other combinations. Remember, when all else fails (note: this would require trying "all else" first), try the double-log plot. Leave the graphs that you use to evaluate the transformations in your spreadsheet so that I can see the evidence for your conclusions as to which transformations to apply.
Once the transformations are complete, and the final regression analysis completed, the resulting relationship must be back-transformed if you transformed the dependent variable, so that it can be graphed as a line along with the raw observations displayed as points. The back-transformation is just making sure that your function for the line is expressed in terms of Y. If you only transformed the independent variable, just include that transformation as part of the final function. For example, if you did an inverse transformation for X, your equation would be Y=b(1/X)+a. If you transformed the dependent variable, you need to simplify the entire equation to express in in terms of Y. For example, if you did a square root transformation of Y in addition to the inverse transformation of X, your regression equation estimates the square root of Y, and so you would have to square both sides to back-transform, making the equation: Y=(b(1/X)+a)2.
Alternatively, once you have the column of estimated Ys from the regression on the transformed variables (Y-hat), you can just do the back tranformation on the Y-hat values. So, for the above example, squaring the Y-hat values is the equivalent of using the equation:Y=(b(1/X)+a)2.
Download this weeks Excel workbook HERE. The first worksheet, "abs", contains data generated for a standard curve. This is an application of regression that most people will be familiar with. In this instance known concentrations of a protein were measured for their absorbance at 450 nanometers in a spectrophotometer. The function that describes this relationship, which is generated by regression analysis, will then allow the concentration of protein from unknown samples to be determined from their absorbance at 450 nm.
You may compare transformations visually, i.e., graph the transformations and see whether they produce a straight line. This will allow you to quickly eliminate the poor candidates.
Remember: you only will need to compare r2 values if you cannot clearly distinguish between valid transformations.
Question 1: This relationship clearly violates the linearity assumption. Use transformation to produce a linear relationship, find the function that relates the 2 variables, report the complete results (t-test results, r2, and equation), and graph the relationship.
The second worksheet, "copper", contains data pertaining to the relationship between the size of individuals in a litter of snakes (SVL), and litter size (number of individuals in the litter) for the Australian highlands copperhead, Austrelaps ramsayi. This demonstrates one interesting application of regression: the examination of residual variation. To remove the effect of the mother's body size on litter size and juvenile SVL, regression analysis was conducted on the relationship between the mass of the mother and litter size, and between mass of the mother and offspring SVL. The data presented are the residuals from those relationships. The question is: how much of the residual variation in offspring SVL can be explained by the residual variation in litter size? I'll let that sink in for a minute...
The issue that this creates is that there are negative values for the residuals, making certain transformations mathematically impossible. The specific problem with this data set is a violation of the homogeneity of variance assumption, and so in order to facilitate transformation of the dependent variable, there is an additional column ("adj SVL resid") that simply adds 0.198 to each SVL residual. This means that you will have to account for that in terms of your estimate of the Y-intercept as part of back-transformation of the data. I'll let that sink in for a minute...
Once again, you may make visual comparisons to narrow down your choices, and only compare r2 values for the closest candidate transformations.
Question 2: Use the transformation that best stabilizes the variance (provide graphical evidence of this), and use regression analysis to examine the relationship between litter size residuals and offspring SVL residuals for a significant negative relationship. Be sure to include the graph of the results.
The final data set is from mark-recapture data on keelback snakes (Tropidonophis mairi), looking at the number of recaptures of an individual (as a proxy for survivorship) as a function of SVL. This particular data set appears to have both linearity and homoscedasticity issues...
Question 3: Find a transformation to stabilize the variance (if necessary), and a transformation to linearize the data, and use regression analysis to examine the relationship between SVL and the number of recaptures for the keelback snakes. Be sure to include a graph of the results.
As always, save your Excel and Word files as yourlastnameex11 and submit them via Blackboard.
Send comments, suggestions, and corrections to: Derek Zelmer